Dependencies on a Hadoop Ecosystem
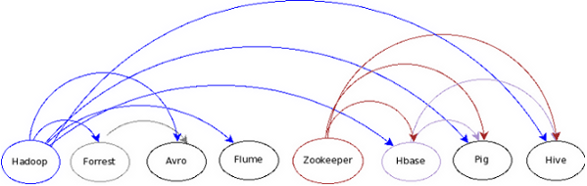
When building a Hadoop cluster and all other Apache projects related to it, it might be tricky to know what to install and how to install. You first should understand your data, and what you want to do with it. If you have log-like data, that keeps increasing all the time, and you have keep updating it to the Hadoop cluster, you might want to consider Flume. Apache Flume is a distributed deamon-like software ( and for that presents High Availability) that can keep feeding data to the Hadoop cluster. If you need a no-sql radom read/write database you can use Hbase , implemented based on Google's BigTable database. If you have relatively structured data and you want to do query-like analyses on it, you might consider Pig or Hive . Both work on top of the Hadoop cluster, executing commands instead of Java written MapReduce jobs. They both furnish their own language to execute such commands. Pig uses a textual language called Pig Latin, and Hive uses a syntax ver

